Lecture 1B - Scheduler/Software/Storage
Interacting with a scheduler
As shown in the previous note, high performance computing clusters are characterized by a (or several) login nodes. The nodes serve as the gateway to the rest of the cluster. To gain access to the compute power within the cluster, you must “reserve” time on a compute node. This is done through a resource manager commonly termed a scheduler.
On ARC systems, we are migrating to SLURM which stands for Simple Linux Utility for Resource Management. You can think of SLURM much like you would your calendar. SLURM tracks the state of the resources defined for the cluster and tries to optimize the utilization of those resources given use policies. If configured, SLURM also physically isolates users from each other so they do not inadvertently create resource conflicts.
There are two main scenarios we are concerned with –
- you want an interactive job to work much like you would on your local laptop
- you want to submit a job for execution later
Before we start a job, we probably have a couple of questions:
- how are the resources organized
- what resources are available
Cluster organization
The compute nodes are organized into queues or partitions. These partitions are usually dedicated to hardware differences or user needs. To see what partitions are setup, we need to log into a cluster and then query SLURM. In a browser, go to ood.arc.vt.edu (you must have the VPN on), cluster tab and choose TinkerCliffs.
Now type:
sinfo -s| PARTITION | AVAIL | TIMELIMIT | NODES(A/I/O/T) | NODELIST |
|---|---|---|---|---|
| normal_q* | up | infinite | 209/91/2/302 | tc[001-302] |
| largemem_q | up | infinite | 0/7/1/8 | tc-hm[001-008] |
| preemptable_q | up | infinite | 209/96/2/307 | tc[001-307] |
| dev_q | up | infinite | 209/96/2/307 | tc[001-307] |
| interactive_q | up | infinite | 0/1/0/1 | tc308 |
| intel_q | up | infinite | 0/16/0/16 | tc-intel[001-016] |
From this, we can see there are many queues/partitions we can potentially submit to. How do you choose? For ARC, we publish the hardware specifics on our website, arc.vt.edu, Resources, Computing Systems. While there, you should look at queue limits. For this class, we will use normal_q. Let’s submit a job.
salloc --partition=normal_q --nodes 1 --ntasks 2 --cpus-per-task 3 --time=01:00:00 --account=stat5526-fall2020
exitOk, what did we just request?? We requested 1 hour of total time on a single node. On that node, we want to have available 2 potential tasks with 3 cores reserved for each task, ie a total of 6 cores. We will talk about these flags and settings more later.
An important node, what happens after an hour? Well, SLURM kills your job, cleans up the local node and if you had anything in progress, it is basically similar to holding the power button on your local computer, dead.
When you typed that salloc command, what happened? You console session transfered from the login node to the compute node. If you type exit, you will go back to the login node.
Try this, from a fresh session, ie you are on the login node:
hostname
salloc --partition=normal_q --nodes 1 --ntasks 1 --cpus-per-task 1 --time=01:00:00 --account=stat5526-fall2020
hostname
exit
hostnameWhat happened?
Software
On HPC systems, system administrators install many of the software packages we need. The reason is that many packages try to install into system directories. If we were to open those up to all users, we would end up with many tangled conflicts. To fix this issue, we use a module system for software deployment. This allows users to load only the software they need and further allows for several versions of the same package to be available. On TinkerCliffs, we use a package manager called LMOD along with EasyBuild. For us, I have created the base packages we will use and made them available. Ultimately, we will use a container (more on that later), but to see the module system in action, do the following from any node on TinkerCliffs:
module list
R
R/4.0.2-foss-2020a
module list
R
module reset
module listWhat have we seen/learned?
Storage
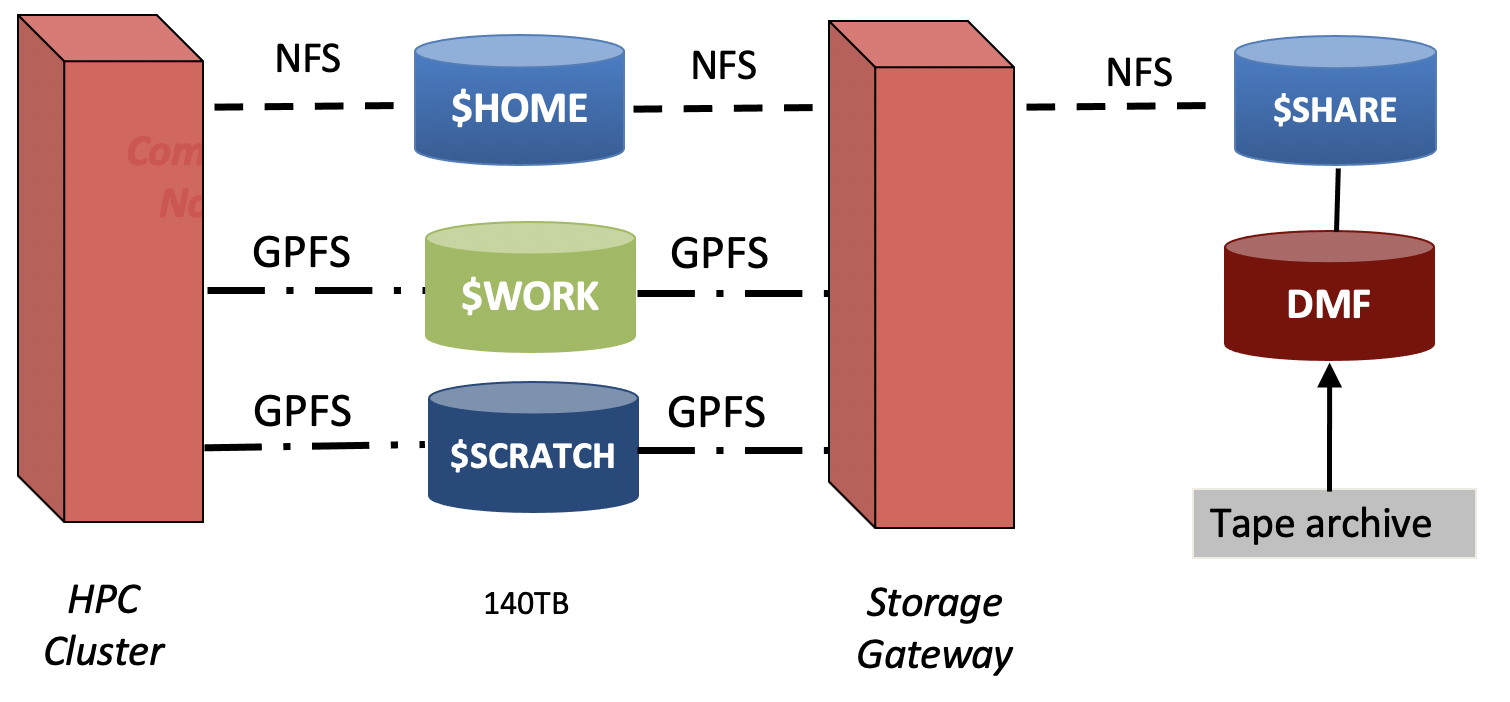
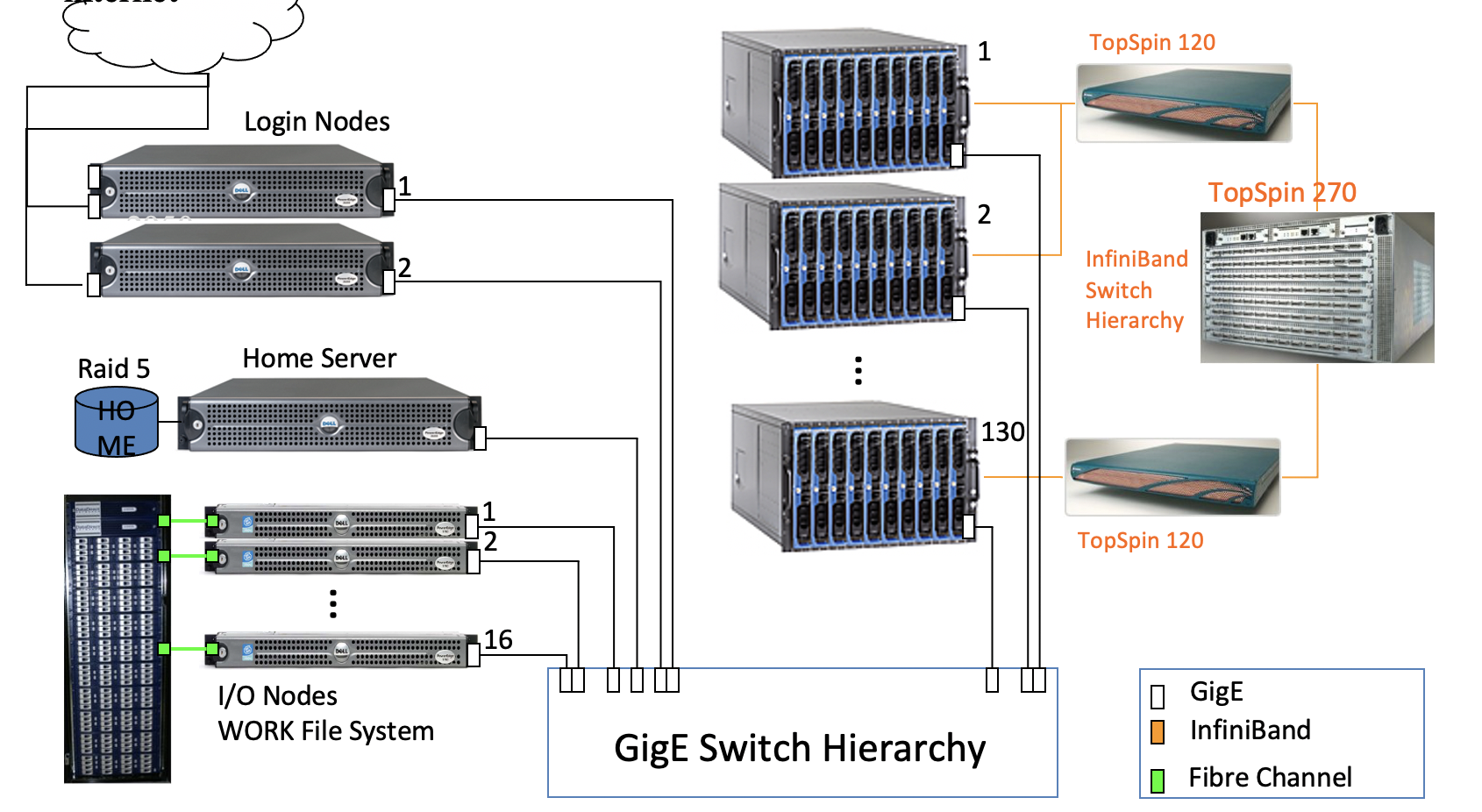
HPC system storage
As depicted, there are several different disk stores available the compute nodes. These are made available through high speed connections (ethernet or infiniband) and are shared across all the compute nodes. You should be aware that ALL of your jobs can see the same storage, so you may need to think through temp file names etc so that you don’t corrupt your data. The diagram is somewhat data, current networked file systems on TinkerCliffs are:
– think of this like /Users/you on a Mac – think of this more like a work directory you may make on your local system – think of this like your Google Drive, good place to work with others
Local storage
In addition to the networked file systems, each compute node, much like your laptop, contains a hard disk and RAM. Each of these can also be accessed. We do so via environment variables. We use environment variables because the directories we have access to change according to the job names. SLURM deletes these directories when our jobs finish as a cleanup step, ie be sure to copy and data from local to networked storage if you want to keep it. The two storage locations on a local node we will use are:
$TMPDIR – think of this like c: on your local machine $TMPFS – this is the RAM of the local node, but we can write to it!!
Let’s try it. From the console, do:
hostname
alias la='ls -lah'
la
la /
pwd
salloc --partition=normal_q --nodes 1 --ntasks 1 --cpus-per-task 1 --time=01:00:00 --account=stat5526-fall2020
la
alias la='ls -lah'
la /
cd $TMPFS
pwd
exit
pwd
cd /
df -h